Computer Vision Algorithms and Systems
My Learning from Computer Vision Algorithms
As I progress through my journey in the Computer Vision Algorithms subject, I’ve come to appreciate the intricate details that shape how machines perceive and interpret visual data. This subject has offered me a comprehensive understanding of how light, color, and various algorithms work together to enable computers to perform tasks that once seemed exclusive to human vision. Here’s a breakdown of some key concepts and techniques I’ve learned:
Understanding Light and Color
Light is more than what we see; it’s electromagnetic radiation that interacts with our eyes, triggering processes that result in color perception. Human eyes contain rods for low-light vision and cones that detect color. The cones come in three types, each responding to different wavelengths of light, forming the basis of the tristimulus theory. This theory suggests that any color can be represented using three values corresponding to red, green, and blue (RGB). This understanding is crucial in computer vision, where color models like RGB, CIE XYZ, and CIELab are fundamental to image processing.
The Mechanics of Image Sensors
In exploring how images are captured, I learned about image sensors like CMOS and CCD, which convert light into electric charges and then into digitized image samples. This digitization process involves converting continuous signals into quantized samples, with proper sampling rates essential to avoid aliasing.
Digital cameras use color filter arrays (CFA) to capture accurate color information by representing the real world through three color channels—red, green, and blue. Gamma correction maps these quantized samples into a domain that our eyes perceive as uniform, enhancing digital image quality.
The Concept of Machine Vision
Machine vision involves a multistage process where each stage influences the next. This concept highlights the importance of image enhancement to make images suitable for specific applications. However, image capture often introduces distortions that degrade quality, requiring quantitative metrics to ensure accuracy.
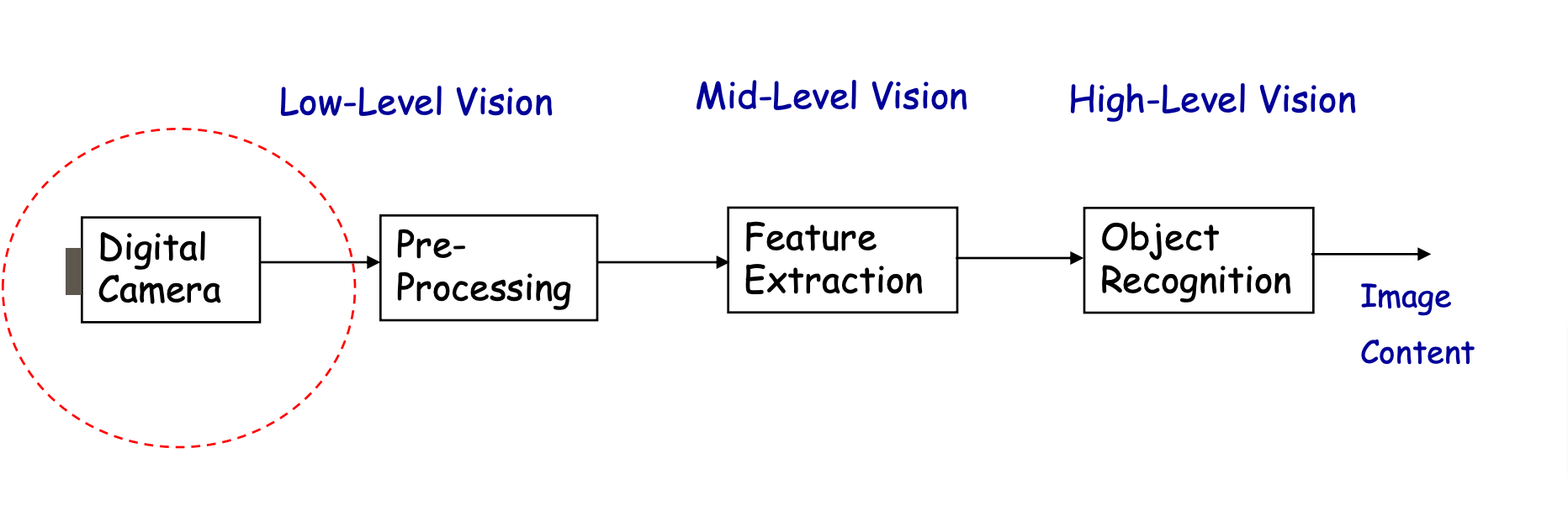
Noise is a challenge in digital imaging, arising from the analog components in cameras. It requires statistical methods for reduction to preserve useful information.
Edge Detection and Keypoint Detection
Edge detection is vital in computer vision, as edges indicate boundaries and shapes. Gradient calculation detects these discontinuities in images. However, noise can affect edge detection, necessitating noise reduction techniques.
The Canny edge detector is a robust method combining edge detection, thinning, tracing, and linking to produce clean edges. Keypoint detection follows, using algorithms like the Harris Corner Detector to identify points of interest in an image. The Harris Detector’s mathematical foundation, including eigenvalue analysis, ensures reliable keypoint detection.
Advanced Techniques: SIFT and Hough Transform
The SIFT (Scale-Invariant Feature Transform) algorithm is crucial for detecting, localizing, and describing keypoints, enabling robust object recognition across varying scales and orientations.
The Hough transform locates shapes like lines and circles within an image. It converts the image into a binary edge map, generates shape parameters for each edge point, and accumulates these parameters in an array representing the parameter space. Peaks in this array correspond to likely shapes, facilitating shape localization.
Segmentation and Object Detection
Segmentation is essential for object detection, involving methods like clustering-based approaches, thresholding, and K-means clustering. Advanced techniques like mean shift clustering and normalized cuts (NCut) provide more precise segmentation in complex scenes.
Object detection involves identifying and localizing objects within images. Techniques such as face detection and pedestrian detection use specific features and classifiers to recognize and categorize objects, crucial for applications like surveillance and autonomous driving.
Motion Estimation and Optical Flow
Motion estimation determines the movement of objects within image sequences. Optical flow calculates the apparent motion of brightness patterns across frames. Techniques like Horn and Schunck and Lucas and Kanade methods estimate optical flow, each offering different approaches to handling motion.
What I Found Most Interesting While Learning About Computer Vision Algorithms
Studying computer vision algorithms has been enlightening, revealing fascinating aspects of technology and human perception. Key points of appreciation include:
1. The Intricacies of Human Vision
The complexity and capability of human vision are remarkable. I was amazed to learn that our eyes can perceive a spectrum of colors that digital devices cannot fully reproduce. The CIE 1931 color space models human color perception, highlighting the sophistication of our visual system compared to technology.
2. The Mathematical Foundations of Computer Vision
The extensive mathematical framework underlying computer vision is intriguing. Concepts like Gaussian distributions, the Central Limit Theorem, and the Fourier Transform illustrate how images can be analyzed as signals through mathematical lenses. This approach connects computer vision to broader areas of signal processing and applied mathematics.
What I Don’t Like
While foundational formulas and algorithms are crucial, many have become somewhat redundant with the rise of deep learning and Convolutional Neural Networks (CNNs). Modern approaches have simplified and automated tasks that were once complex and algorithm-intensive. Consequently, some traditional methods and mathematical formulations have become less prominent, shifting the focus toward leveraging deep learning models for advanced and efficient image processing.
Overall Experience
I achieved a Distinction in the course. I feel significantly more knowledgeable about computer vision than before and am eager to apply this knowledge in practice.
Enjoy Reading This Article?
Here are some more articles you might like to read next: